Data and the Dinosaur’s Data
Welp, time for our informally scheduled bi-weekly blog!
I figured I’d mix things up a bit and share a little about one of the projects that has been keeping me busy for the last few weeks: recovering data from an almost-literal dinosaur.
Disclaimer: this blog entry will contain significant portions of technical information, but I’ll try to make it easy to understand. It's also a long read. Sorry about that.
Act 1: Not so simple
A few weeks ago, I received a call at work from our sales rep regarding potential work at a local business. The company in question was looking to migrate away from their old accounting software and wanted assistance in exporting the data to use in a new system. Sounded simple enough, especially when they sent a picture of the monitor screen: CRT monitor with the classic blue background and white text. Looks like a custom software running in DOS, should be a cinch to get the data to examine. Probably stored in a text file, I was guessing. 20 minutes to find and download the files, tops. I grabbed a few 3½ floppies from my collection in my basement and headed out to have a look.
Oh how wrong I was.
When I get to the company, they lead me outside, around the back of the building to a maintenance area, into a back office that looks like it could have been from the 80’s or 90’s. Carpet floor, drop ceiling doing its best to not show its age, wooden panels on the walls. A metal and cloth padded swivel office chair missing a wheel, armrest only held together with translucent packing tape. Hardware from industrial control boards on shelves lining the walls, leading the way to an unassuming stout white metal desk doing its best to hide under a mountain of paperwork. A decently “modern” flatscreen CRT stands proudly in the center of the paper jungle, joined by its offwhite companion PC that appears to be operating solely on a sheer stubborn determination to survive, its hard disk whining loudly in protest. The CRT is on and shows very prominent ghost lines of text, testifying to the fact that this screen is very rarely if ever turned off.
As expected, the PC had a 3½ floppy drive, but it also had a few more modern surprises like a CD-ROM and a zip drive. At this point I’m pretty well convinced that this is going to be an easy in-and-out job. CD-ROM drives were just becoming standard about the time that Windows 95 was released, so surely this couldn’t be too old! No mouse, just a keyboard, further solidifying my prior assumptions of it being a DOS system. As I start navigating around, though, things become less and less clear. DIR doesn’t work. The command prompt is formatted wrong. LS does nothing. HELP is not the MS-DOS help program. VER does nothing. What is this thing!?
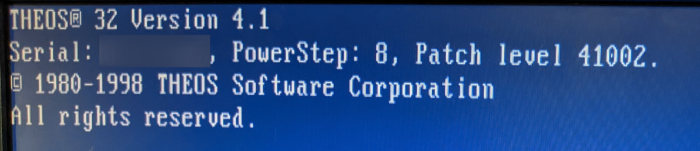
I find a touch of reprieve in the help catalog - in the file copy/backup/disk command pages I notice mention of THEOS-formatted disks. A cursory search lends me a user manual from 1985 detailing how to use THEOS8 5.6 from 1983, and I quickly realize that this is a much bigger project than I had anticipated. This is a lost piece of computing history, from the ages when the Commodore 64 was everywhere and companies were trying to find cost-effective tools to conduct business in the new age of computers, developed as a cheaper alternative to UNIX with multi user terminal support.

Excerpt from the THEOS86 user manual
At this point, it’s pretty evident that this is going to be a much larger project than I had expected. Pulling data from this system will require at best a long series of learning the tools available in this operating system, and at worst may require custom software written in BASIC to extract the data via a serial port. After a little talk with the company owner and fee agreements all around, I shut down the machine for transporting home - reportedly its first time being powered down in twenty years.
Act 2: First steps
First thing first, BACKUP. This machine worries me that it may be on the cusp of failure, simply due to its extreme age. The life expectancy of a modern hard disk drive is about four to five years. Good hard disk drives can be reasonably expected to live for ten years if they survive the wear-in period. This machine has been powered on and running for twenty years, minimum! The accounting software had a copyright 1993 label, so it could be even older than that! I’m actually concerned it might not start up on the first try and I might need to use the hairdryer trick. I set it up on my impromptu bench in my living room, find a donor drive to clone to, and set out to try to boot up an old disk clone program on the machine.

On removing the case cover, I discover a Pentium 2 and an AGP 3.3 slot on the board, so the machine itself is not quite as old as I was led to believe - somewhere between 1997 and 1999. My first hiccup was when I found that the CD-ROM didn’t function - the band that actuated the door and the laser alignment had disintegrated. The CPU and RAM are a tad low for using GParted, too. Not wanting to find if I could hunt down my copy of Norton Ghost, I opted to use a different machine for cloning. I’ve got a faster Pentium 3 stashed away, anyhow. With a USB port, too! Fancy! I even broke out my M2 keyboards for the occasion.

Image in hand, I wonder: can I load files from the image using a file recovery software? Surely I’m not the only one who’s needed files from an obscure file system, right? Unfortunately, searching for options brings up a plethora of results for a “Theos cross-platform build system” program compiler project that started a few years ago. Why they chose that name, I have no idea. Ultimately, the most recent information I could find on THEOS the operating system at the time was from 2002. No file recovery software, no linux filesystem tools, nada. So… will this run in a virtual machine? Maybe I can use screen capture software to extract the information I need, or at the very least figure out what files I need to find.
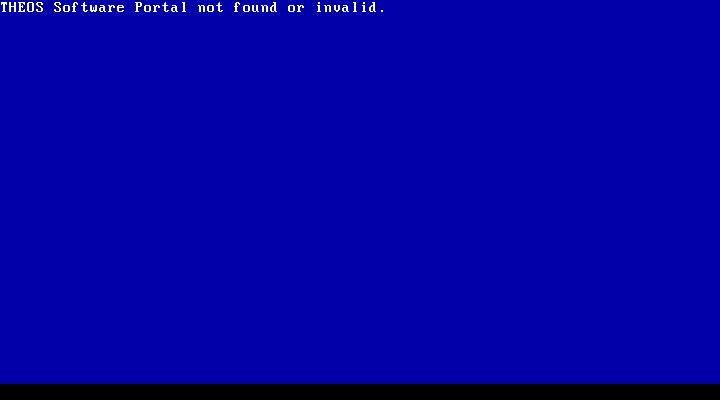
Well yes, but also no. Turns out it looks for a particular chip to be inserted into the computer’s DB-25 (LPT) port as a form of anti-piracy protection.

Ah, 90’s-era anti-piracy measures. I’ve not missed you. Some companies still use stuff like this for expensive software licensing (nowadays they’re on USB drives), but finding something like this for an old operating system is new for me. My work computer does not have a DB-25 port, so I was not able to forward the hardware to the virtual machine. Not that I needed to in the end, but it would have been nice. I’ve blurred out the serial number here, since it’s theoretically possible to trace it back to its owner if those records still exist somewhere, but it looks something like 102-12345.
Well, what else can I use the image for? How about I take a peek at the disk to see if I could manually extract what I needed?

Jackpot. Sorta. The files on the disk seem to be null-padded binary streams, but they’re pretty simple to decode once you work how many fields there are and how large each one is. Especially since most of the data is ASCII text. For manually extracting files from the drive image, one aspect that makes things easier is that most of the files are visually identifiable. The drive is formatted in such a way that the empty space is just a repeating sequence of bytes: 0110111011100110
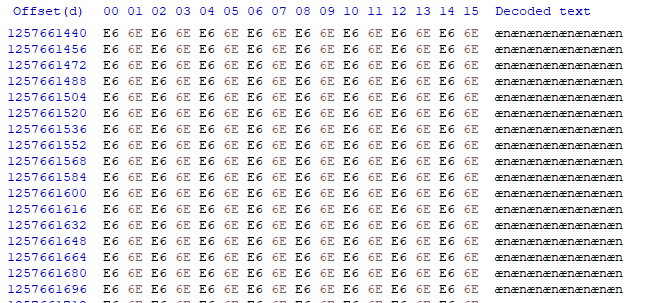
This makes it easy to verify if the spot you’re looking at is null space or a file, but simultaneously doesn’t guarantee that the file you’re looking at isn’t shorter than what you’re seeing - the null pad only happens on format, not on file erase. I found a few instances where a larger file was overwritten with a smaller file, so the end of the file was more or less garbage I’d have to manually decipher to figure out the actual end of the file. I did happen upon the minimum allocated block while using this trick to browse through files: 265 bytes.
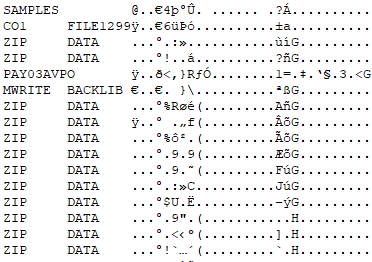
The trouble then becomes working out how to find all of the files I need and how long each of them is. And what data means what. While browsing through the disk dump, I find some source files referencing a “ZIP.DATA” file. Maybe if I can find that file, everything else will fall into place? This requires more investigation.
At the head of the disk, there’s a classical MBR record with a single partition. Due to the size of a sector there's a sizable null-zone before the actual partition starts. The next thing on the disk is what I presume to be a chainloader for the file system, then there’s a file allocation table.

File names seem to be stored in a space-padded 16 bytes, with 8 for the first part, and 8 for the second, or what we would call the file extension. A file entry is 64 bytes total, presumably with data such as date, time, filesize, and location in there somewhere. Unfortunately, there also seem to be a large number of “ZIP.DATA” files. This is going to be a bit hard to decipher with the little information I have, especially since I’m not too keen on reverse-engineering the bytecode to figure out how the system runs. To the dinosaur dig!
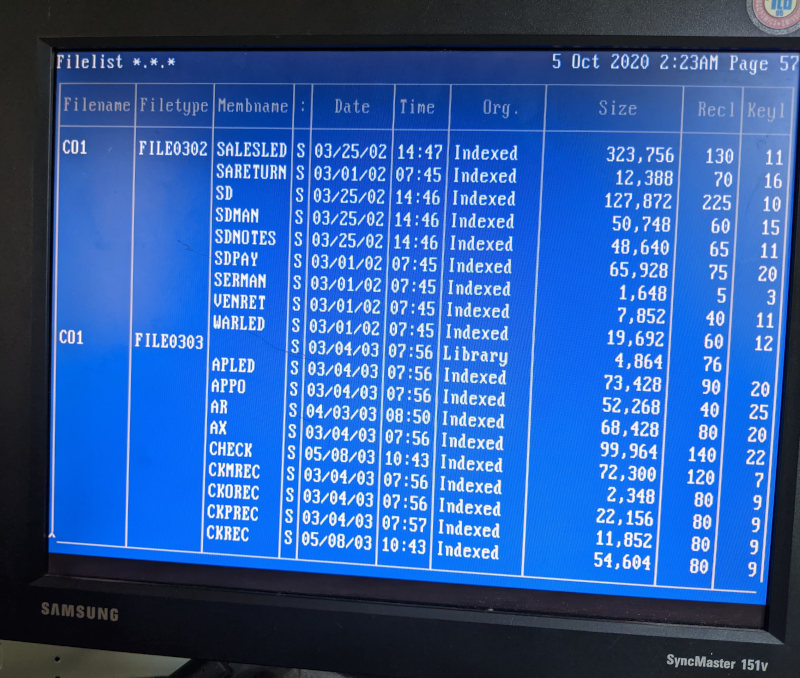
For the majority of a Saturday afternoon and late into the evening, I worked through some of the mysteries of the system with help from a friend, teasing out the operational workings of the system. For example, there’s a FILELIST command in the help screen, but running that command returns without printing anything to the screen. Digging deeper into the documentation available, we found that you have to specify which file pattern to list out, and optionally which drive to list from. It uses a curious syntax, though. Using FILELIST *.* shows all of the files on the drive.. mostly. Well, files that have been user-created. It doesn’t show files that you don’t own. Having seen the file table myself, and also knowing that there’s a custom program on the machine that’s not showing up in that listing, we dig a little deeper and discover that a portion that we had thought was an example optional argument was in fact the actual syntax. The command to list all files and all “library” file members on the machine is FILELIST *.*.*:S (PUBLIC - easy, right?
The way this system stores files is mostly flat, no folders. It supports folders, but doesn’t seem to actually use them. It prefers to use “Library” files instead. I’m not entirely sure what the difference is, aside from how you reference them. They store their member files in very much similar format on the disk. According to the documentation available, you’re supposed to use libraries to “group files that are similar in nature” - you know, like what most people use folders for. The system won’t let you store other libraries or folders in a library and gives you control over the initial table size, which is probably the biggest difference. What is most interesting about the system, though, is that it natively supports a database file format. Those null-padded files I discovered on the disk aren’t due to any special programming in the accounting software, but are rather data files that the system itself supports out of the box! Neat!
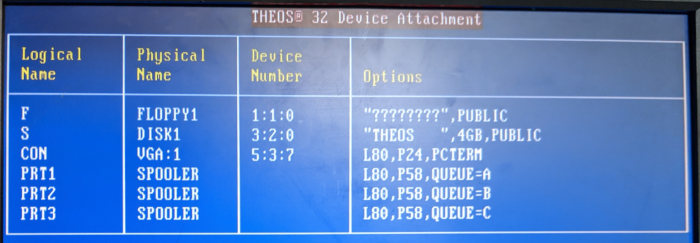
We eventually find how to copy files to a floppy drive, but, as with all things with this system, there’s a catch: the floppy must also be formatted in THEOS format. It won’t read a FAT-formatted floppy disk. Welp, it’s better than nothing! We start by copying files one by one, one file to a floppy, then cloning the floppies using rawwritewin running on an XP box for later analysis. Eventually, though, we also discover that the FILECOPY not only has the (PUBLIC option, but it also supports a mysterious (EXPORT option that’s supposed to export files in a DOS-compatible format. We very shortly discover that it simply means that it exports database files, which it calls “Indexed” files, into a comma-delimited text file format.
FILECOPY DATA.*.*:S DATA.*.*:F (PUBLIC EXPORT
Score!
Feeling a little braver, we try to copy an entire database library onto a floppy. It takes about 6 hours to complete due to how it writes: find a free spot, write to the file table, write a 256-byte chunk, update file table with file size metadata, repeat. Given the size of the file portion of the disk, this means it could take 11,392 write head position changes to fill a floppy disk. Floppy drive heads are not quick. Amazingly enough, all of the files for the specific database we needed just nicely filled one floppy. Which is really fortunate because, as I discovered later, the FILECOPY program doesn’t ask you for a new floppy if you run out of space - it just skips to the next file and ignores files that are too large to write.
Act 3: The technical bit
So now that I have all of these files in an image dump, how do I get them out of there? I really don’t want to manually export by hand the 120-some files that are now contained in this itsy bitsy image file. Plus, what were to happen if we needed more files later? The system writes files sequentially and uses the first available free disk space, but picks a random free slot in the file table when writing files, so the order of files in the list won’t match the order of files in the disk. Keeping track of the order of files being written isn’t a great use of time, especially when some libraries can take six to twelve hours to write to a 1.44MB floppy disk. And I’m pretty sure I missed some while keeping track of the first batch.
Solution? Reverse engineer the file table, of course!
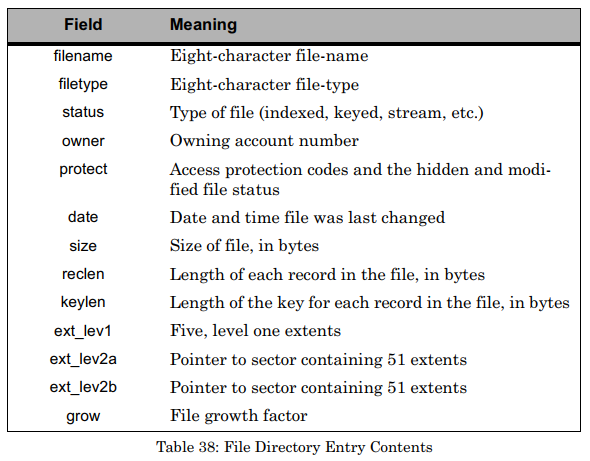
Before I get too far into this portion, I’m going to explain a little about how computers store data. Disk partitions are set up by a partition table not too dissimilar to a file table, but THEOS doesn’t use partition tables, so I’ll skip that bit. Once you’re in a partition, one of the first blocks of data stored is an index of the files stored on the storage medium. At its most basic form, it can be thought of as a chapter listing at the front of a book: There is a file named X that you can find if you skip to position Y that is L bytes long. There’s more there, too. If you’ve ever looked at a file’s properties, all of that information you can see there - the location, size, size on disk, created, modified, accessed, security access, file attributes - are all stored in this file index table. (If you’re looking at the properties of an image, extra data such as image resolution, size, etc is stored in the file itself).
Anyone familiar with computers will also know that data is stored in a binary format - when a computer reads a text file, they are simply looking up what value 65 is supposed to look like on your display screen and sending to the display driver instructions to change pixels on the screen to match the A glyph you’re familiar with. Computers don’t know what text is - not on an intrinsic level. Computers read numbers and look up what those numbers are supposed to mean on instruction tables. Computers read and store numbers as sequences of 1’s and 0’s, otherwise known as binary.
Here’s the next bit of knowledge that will come in handy: we humans tend to read numbers from right to left. I don’t mean the names of numbers, mind you - I mean how the powers are arranged. 123 base 10 is 3 * 10^0 + 2 * 10^1 + 1 * 10^2. In mathematics when you are reading numbers in other bases, this rule remains constant. 123 base 8 is 3 + 2 * 8^1 + 1 * 8^2. If you were to try to translate binary 01001000 01000101 01001100 01001100 01001111 into text, you’d start by converting each sequence into numbers. Pro tip: you can actually ignore the upper three bytes when converting binary to ASCII. Uppercase is a 0 in the 32’s position, and lowercase is a 1.
01000001 is an A
01100001 is an a
Binary is then read from right to left in sequence: 1, 2, 4, 8, 16, 32, 64, 128, etc. The value that most impacts the final value is on the leftmost position. This is known as Most-Significant order, or in binary “MSB” (Most Significant Bit). In this example, throwing out the upper three bits, we have 01000 00101 01100 01100 01111. Counting from right to left, the first number is easy: it’s the 8th letter of the alphabet. H. Second is 1 + 0 + 4 = 5. The 5th letter. E. The next two are the same, no 1’s, no 2’s, one 4, one 8, 4 + 8 = 12. L. Last character is 1 + 2 + 4 + 8 = 15. HELLO!
Storage controllers store data in 8-bit segments known as bytes. A byte can only count from 0 up to 255. That’s not particularly useful when we need to be able to count big things, like how much money you have in your bank account. So computers chunk bytes together to get bigger numbers. An Integer (a whole number) is four bytes squashed together, and can count all the way up to 4,294,967,295. Not quite up to Jeff Bezos. A long integer on a modern 64-bit system is eight bytes, which can count up to 18,446,744,073,709,551,615. That’s a number large enough you could count all of the money on earth, hundreds of millions of times over!
To make working with computers a bit easier, we use a 16-base writing system known as hexadecimal, or just “hex”. 0 through 9 are just as you’d expect, but we also have A = 10, B = 11, C = 12, D = 13, E = 14, F = 15. A value of FF in hex is 255, or 11111111 in binary. If you were to write the number 12345678 as a hex number, you’d expect a value of BC614E (trust me on this here). Because bytes conveniently fill out every two hex digits exactly, the bytes are then BC 61 4E.
Now, the order that bits (the individual 1’s and 0’s) in a byte are written and read from storage mediums are nowadays handled by the storage controller (and thankfully this system is “modern” enough to have an IDE drive, as IDE drives were when that control was relegated to the drive itself rather than the computer), but the rest of this bit of information becomes most relevant when I mention that computers don’t always read numbers from right to left in the LSB to MSB order we’re used to seeing. A lot of systems, especially older ones, read numbers from left to right. Instead of writing the biggest part of the number first and working their way down, known as “Big endian” format, many computers and computer programs tend to write numbers starting at the lowest digits first. When you read and write from the least significant byte to the most significant, otherwise known as “Little endian,” it looks like you’re reading the number backwards. Our value of BC 61 4E would look like 4E 61 BC when looking at the disk. This can be a bit counter-intuitive, because we don’t normally read or write numbers like “123” as “321” in everyday life.
This can make finding and reverse-engineering binary streams significantly more difficult as well, since not only do you need to figure out which bytes mean what, how many fields there are, and how many bytes you need for each field, but you also need to figure out if numbers are stored in big-endian or little-endian format. Ultimately, this means a lot of guess-and-check coupled with a not-insignificant amount of pencilwork.
Act 4: The THEOS32 File Table, Unraveled
With all of that ado, I’m just going to gloss over most of the order of events that got me this far into deciphering the table itself. The floppy images that I made first while testing turned out to be a great help in deciphering the locations of fields such as the position and file size, and I was able to translate those over fairly well to the full dump of the export files as well as the hard disk itself.
The first thing that jumps out when looking at the file table is the filenames - ASCII-encoded, they stick out of the binary data like a billboard in a cornfield. In fact, the spacing for the filenames was how I first figured out how large the file records are: 64 bytes. Filenames are stored as two 8-character strings, with the 2nd part of the file being all spaces for files where an extension isn’t defined (in the main index) and all nulls if it’s a library file member (more on that next). These are stored almost just as you’d expect, from left to right and with spaces padding the empty space. I’m not sure why the file names aren’t null-padded, but it works. Also made it really easy to tell how large the strings were supposed to be.
As far as I was able to determine, there are 10 different types of files possible on a system:
Yes, the file table even tracks deleted files. My going theory on this is maybe it tracks the empty spots for later cleanup with another utility, or perhaps it evaluates if the space leftover by a deleted file nicely fits a new file to be written? In either case, and rather by accident, I found that any file marked as type 0xFF could be ignored entirely, since I wasn’t looking to recover deleted files. I never did figure out what a “relative” file is supposed to be. Most samples I could find were just null-padded files, and the user manuals had no information about them other than the fact that they exist. They do have a record length, but not a key length, which makes me wonder if it’s a simpler database format. The CREATE command doesn’t even support creating a relative file, which only deepens that mystery.
Indexed files are the null-padded database files I discovered earlier. The index table includes the size of each record and the size of each key. There’s more data in the index file itself about how to read them, presumably in the first 14 bytes, but I didn’t need to work out that portion since I had the export option.
Folders and Libraries share a rather interesting quirk. Remember how I mentioned that I had well over 100 files on a single floppy, and how it had taken nearly all night to complete writing it? Well, as it turns out, the file table for a THEOS floppy isn’t physically large enough to hold file records for 100 files. With a block size of 256, and a record size of 64, we have an available space of 4 records per block:

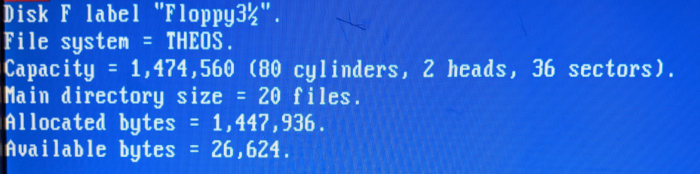
THEOS keeps track of the disk’s cylinders, heads, and sectors in addition to disk label and other misc data. The 256-byte block that tracks this information is kept just in front of the partition table itself. On a floppy, it’s 1024 bytes from the start of the disk. Leaves a bit of wasted space, too, since a boot sector is only 512 bytes. It would seem that the 512-byte space before the disk information is intentional space for including a boot chainloader and they just didn’t think to leave that space offset out of non-system disks. Or they didn’t want to make a different format for storage disks vs THEOS boot disks, I don’t know. On a hard disk, though, it gets even weirder: the partition table doesn’t even start until 32256 bytes after the 1024 byte offset. 31 KiB of empty space. On an addressing format incapable of addressing more than 4 GiB of disk space. Well, beggars can’t be choosers? It’s just how it is. I’m fairly certain this is due to physical disk sector addressing and they didn’t bother trying to reclaim the unused space from the rest of the sector, not that they really needed to. The floppy format is still more efficient than FAT, though - 1471744 bytes to be used for files vs 1457152 for FAT. 14.5K extra storage is quite a nice bonus.
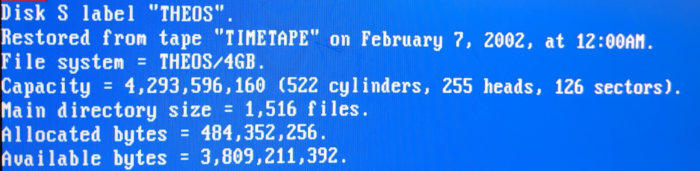
Anyway, see those three bytes I have marked as the Index Allocated? That’s the number of blocks that have been allocated for the file table. A block is 256 bytes - divide that by 64 bytes per file record, and you have 4 records per block. So take the number of blocks multiplied by four and you have the number of individual files that the system is capable of storing. The 05 00 is stored in little endian format, which means it’s 0005 in hex. 5 * 4 = 20 records. 00 7B 01 for the hard drive is hex 017B = 379, which is multiplied by 4 gives us 1516 slots for file records.
No, that scratch isn't on your screen, it's on my bench monitor.
Free is a pretty good price, though - can't complain.
A floppy is only capable of storing 20 files, total!
So how did I manage to get over 100 files onto a floppy without the system blowing up? Turns out the system has a really neat loophole for getting around this limitation: when it creates a library file or a folder, it creates a new file index as a “file” for the main file index, and stores that file index as a file itself. So you can have multiple file indexes located all over the disk, not just at the main file table. In order to use disk space and processing efficiently, it’s also best if you have an idea for how many records you’re planning on storing. These files have to be sought out and loaded fully before the system can use any individual file referenced in there. More on that later, since that’s not important right now. We’re still trying to figure out the main bits here. For the purposes of file recovery, though, this quirk means that we have to be able to load these extra file tables as well as the main index before we can be sure we have the full file listing.
The next bits we need to figure out (or bytes, rather) are the location and the size of the files. This was easy enough to work out after comparing the floppy images with the data provided from the FILELIST command. Interestingly, both the file size and the block allocations are stored in the file table, even though these numbers are usually in the same block. (The reason why this is becomes apparent later in deciphering the table). These numbers are stored on disk in little-endian, so you need to read them lowest-order first. At this point, this is the information we know:

The record length and key length fields were pretty easy to figure out, simply comparing the system’s file listing with the file index. It is right between the fields for file size, after all. Found by chance, really, since I wasn’t actually looking for those numbers. Off to the right are more bytes, but usually they’re nulls. The very last byte is usually 03, but sometimes 00. That last byte was one of the last ones I figured out, mostly because it has absolutely no bearing on the file’s existence, try as I may to isolate its purpose.
See the bytes I have marked as Modified Date?? I’d figured this out by comparing file records and what changed and when, but at this point I still didn’t know how to read it. It seemed to be a big-endian number, based on which bits were changing as the file dates changed (the right-most bytes changed first, and seemed to count progressively up as time passed). The only value stored in big-endian in the file header, or anywhere else I'd found on the system. Interestingly, it seemed to count seconds, even though the operating system would not print out the file modified date with a resolution to show seconds.
My first thought was maybe this is simply the number of seconds being counted. It’s the most efficient method of storing a time (bytes utilized vs the amount of time that can be measured), and the times were close enough to be seconds. However, when mapping out the seconds to times to try to map out what the offset should be, things started to get weird. Times didn’t match up with files adjacent. Files written at the start of a day were drastically different from files at the end of a day. The values continued to count upwards, but the rate at which they counted up was itself variable - an extra second every 7 or 8 seconds, or even in-between. I was able to confirm that the first two bytes were definitely tied to the date and the right two bytes were tied to the time of the day, but none of the methods I tried in using the bytes as numbers translated to anything coherent.
I then had the idea to break the bytes down further into binary, just to see what bits were set up and how they were laid out. This is when I made a breakthrough into the date storage format: it wasn’t a number at all! It’s a series of exact-size number fields squeezed into a binary stream!
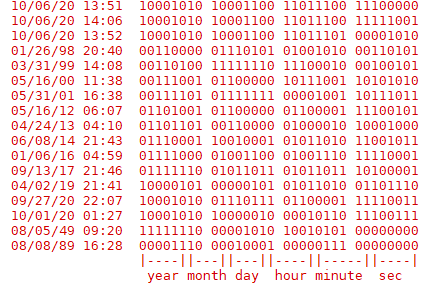
6 bits for the number of seconds. (0-63)
6 bits for the number of minutes. (0-63)
5 bits for the hour of the day (24-hour clock). (0-31)
5 bits for the day of the month. (0-31)
4 bits for the month of the year. (0-15)
6 bits for the number of years since 1986. (0-63)
They stored six numbers into a space you’d expect to see only one or two. This has some interesting consequences: since we’re storing the exact numbers, we don’t need to do any calculations to decipher the calendar date from an offset, we just trust that the system calendar had the correct date when written. Binary operations to extract those numbers are very quick compared to the multiple division operations and some table lookups to determine a date from a seconds count. We also save 4 bytes while keeping our direct number method, freeing up valuable file record space. File modification dates are written after the system has completed writing all of the data, too, so the seconds value is always a tad off when writing to a floppy.
Unfortunately this method fails when trying to translate the part of the partition label that I’m sure is used for the recovery date. The day and month line up, but the year is wrong. Maybe the offset year for backups is different from system files? If so, the offset year would be 1995, which seems to nicely line up with THEOS32’s release. Not sure why the system would use two different offsets for dates, but I would presume to assume it would be related to disk backups being new to THEOS32. Could be wrong as I only had this one system to work with and didn’t particularly feel like risking the integrity of the data to sate my curiosity.
All of the important bits done, right? We have the file size and the location, and we even cracked the file date for funsies. Let’s roll!
Except, some files I was recovering from the disk image weren’t quite right. While spot-checking some of the data I noticed that some of the files seemed to be getting cut short. Words or numbers getting cut before the line finished. I double-checked the file extraction code, and that was definitely the whole file. Kinda. The whole file that was stored in the blocks referenced in the offset. The file just ended at the 256-boundary. The most notable example of this was the SYSTEM.THEOS32.ACCOUNT file - a system file where THEOS32 v4 keeps all of the account and login information for the operating system. It was missing the user account that I had been using to log into the machine with. Something was amok.
Re-examining the file table, I noticed that the files that were messing up had more data after the block offset bytes. I had previously been ignoring those fields since they were always null when examining my floppy images, but I noticed a pattern: the extra data always lined up in 5-byte increments. The same number of bytes needed to store an offset and block size. Sure enough, after parsing the integer values and jumping to the blocks indicated, there was the rest of the file! I added code to load all of those extra blocks together, looping to the end of the file record for 6 fragments (one byte leftover, plus the end byte), and ran again for just the oddballs. Most of the files then loaded correctly, even the account file, but there were still some oddities. Some of the files had an allocated space in where I assumed was fragment #6, but an offset that claimed to be in the disk header space. Where absolutely no files should be stored, ever.
About this time, I happened across a security system vendor that happened to have a user manual for THEOS32 4.1 available on their website. Far more helpful than the 1985 manual for THEOS8. This turned out to be immensely helpful for finishing the filetable deciphering as it actually contained some clues as to how to expect the file table to be read:

So those last 6 bytes are not a file segment record at all, but rather are two optional pointers to a 256-byte block on the disk containing up to 51 more block segments for a potential of 107 individual file fragments for a file. The last byte in the file record is a number signifying how much more space should be reserved each time the file needs to be expanded to store more data, expressed as a % of the current file size. This “grow” marker is a floating point number expressed as two nibbles, 0-9, one for each half of the decimal. 03 would mean the file should allocate an additional 30% of the current size of the file, and 30 would be 300% (it doesn’t support mixed fractions like 330%). Not needed for file recovery, but still a really interesting look into how this system was designed to work.
With that work out of the way, I was finally able to fully load in the files from the file table. With only two remaining unsolved fields, why stop now? I wrote a bunch of dummy files to a floppy and used the CHANGE command to set the permissions one by one on each, then dumped the floppy image for inspection. Bitfield. Solved! User-Read, User-Write, User-Execute, User-Erase, Other-Read, Other-Write, Modified-Flag, Hidden-Flag, in that order. The users table I ended up getting a tad ambitious and actually loaded in the full user table from SYSTEM.THEOS32.ACCOUNT, just so I could print it out and make it look nice. Interestingly, user passwords are stored in 8 bytes, which theoretically means it should be trivial to crack. It clearly uses some byte padding mechanism, since most of the short passwords in the table had the same 3 or 4 last bytes.
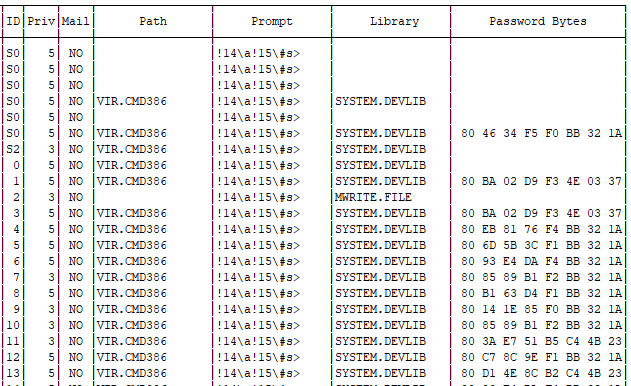
The “Priv” number here is how the system segregates account permission levels. 5 is the super admin, do-anything account, 4 can make system backups, 3 is a general admin, 2 is allowed to write programs, 1 is a general user, and 0 can’t even save a file.
The fact that files are marked with their owning user combined with the fact that there are so many ZIP.DATA files with no folder brought the last bit of information to run file recovery: the system doesn’t have a singular file structure tree. Not in the way that modern systems do, where the admin or root account has access to every file on the machine. Here, if you aren’t the owning user, you can’t see the file. (Well, there’s probably some method to do so, but it’s pretty well hidden). There’s no reason for the system to bother with preventing users from naming files the same as another file owned by another user, because that user has no access to that file to begin with. No user folders. Everything is in the user’s root path. I added a bit of filtering logic to only extract files owned by the target user, and viola! No more file conflicts!

File Table Layout
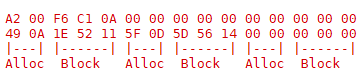
Extended file blocks just repeat the size and position until the end, throwing out the last byte
And that’s about it! I did briefly venture into the world of trying to reverse-engineer the operating system boot code via a GDB terminal hook into QEMU and also briefly forayed into assembly code to try to find the password encryption code, probably 20 hours in all, but in the end those weren’t actually worth the effort. As interesting as it would be to crack, I really do have more productive things to get done. My goal was to get the files out, and to that end I was successful. I have no practical use for a THEOS password decryption utility, and I have no need to run a twenty-year-old machine in a container. Now all that’s left of this project is to reverse-engineer the old database schema and port it over to a modern database solution.
Somebody mention code?
In the interest of sharing with future googlers who may happen across this backwater blog in search of a solution to this oddly specific issue, I offer to you the script I created for extracting files from a THEOS hard disk image or floppy image: https://gist.github.com/jascotty2/940238522a1decd3dc39be6b64579487
Enjoy! ^.^
Resources:
Theos32 4.1 User Manual. THEOS32-4.1-SysRef.pdf.zip
HxD for binary file data https://mh-nexus.de/en/hxd/
Gparted or other linux for using the dd utility for full-disk imaging.
RawWriteWin for cloning floppies http://www.chrysocome.net/rawwrite
MBR format https://en.wikipedia.org/wiki/Master_boot_record
Partition type list: https://www.win.tue.nl/~aeb/partitions/partition_types-1.html
Handy calculator for hex conversions https://www.rapidtables.com/convert/number/hex-to-decimal.html
I figured I’d mix things up a bit and share a little about one of the projects that has been keeping me busy for the last few weeks: recovering data from an almost-literal dinosaur.
Disclaimer: this blog entry will contain significant portions of technical information, but I’ll try to make it easy to understand. It's also a long read. Sorry about that.
Act 1: Not so simple
A few weeks ago, I received a call at work from our sales rep regarding potential work at a local business. The company in question was looking to migrate away from their old accounting software and wanted assistance in exporting the data to use in a new system. Sounded simple enough, especially when they sent a picture of the monitor screen: CRT monitor with the classic blue background and white text. Looks like a custom software running in DOS, should be a cinch to get the data to examine. Probably stored in a text file, I was guessing. 20 minutes to find and download the files, tops. I grabbed a few 3½ floppies from my collection in my basement and headed out to have a look.
Oh how wrong I was.
When I get to the company, they lead me outside, around the back of the building to a maintenance area, into a back office that looks like it could have been from the 80’s or 90’s. Carpet floor, drop ceiling doing its best to not show its age, wooden panels on the walls. A metal and cloth padded swivel office chair missing a wheel, armrest only held together with translucent packing tape. Hardware from industrial control boards on shelves lining the walls, leading the way to an unassuming stout white metal desk doing its best to hide under a mountain of paperwork. A decently “modern” flatscreen CRT stands proudly in the center of the paper jungle, joined by its offwhite companion PC that appears to be operating solely on a sheer stubborn determination to survive, its hard disk whining loudly in protest. The CRT is on and shows very prominent ghost lines of text, testifying to the fact that this screen is very rarely if ever turned off.
As expected, the PC had a 3½ floppy drive, but it also had a few more modern surprises like a CD-ROM and a zip drive. At this point I’m pretty well convinced that this is going to be an easy in-and-out job. CD-ROM drives were just becoming standard about the time that Windows 95 was released, so surely this couldn’t be too old! No mouse, just a keyboard, further solidifying my prior assumptions of it being a DOS system. As I start navigating around, though, things become less and less clear. DIR doesn’t work. The command prompt is formatted wrong. LS does nothing. HELP is not the MS-DOS help program. VER does nothing. What is this thing!?
I find a touch of reprieve in the help catalog - in the file copy/backup/disk command pages I notice mention of THEOS-formatted disks. A cursory search lends me a user manual from 1985 detailing how to use THEOS8 5.6 from 1983, and I quickly realize that this is a much bigger project than I had anticipated. This is a lost piece of computing history, from the ages when the Commodore 64 was everywhere and companies were trying to find cost-effective tools to conduct business in the new age of computers, developed as a cheaper alternative to UNIX with multi user terminal support.
Excerpt from the THEOS86 user manual
At this point, it’s pretty evident that this is going to be a much larger project than I had expected. Pulling data from this system will require at best a long series of learning the tools available in this operating system, and at worst may require custom software written in BASIC to extract the data via a serial port. After a little talk with the company owner and fee agreements all around, I shut down the machine for transporting home - reportedly its first time being powered down in twenty years.
Act 2: First steps
First thing first, BACKUP. This machine worries me that it may be on the cusp of failure, simply due to its extreme age. The life expectancy of a modern hard disk drive is about four to five years. Good hard disk drives can be reasonably expected to live for ten years if they survive the wear-in period. This machine has been powered on and running for twenty years, minimum! The accounting software had a copyright 1993 label, so it could be even older than that! I’m actually concerned it might not start up on the first try and I might need to use the hairdryer trick. I set it up on my impromptu bench in my living room, find a donor drive to clone to, and set out to try to boot up an old disk clone program on the machine.
On removing the case cover, I discover a Pentium 2 and an AGP 3.3 slot on the board, so the machine itself is not quite as old as I was led to believe - somewhere between 1997 and 1999. My first hiccup was when I found that the CD-ROM didn’t function - the band that actuated the door and the laser alignment had disintegrated. The CPU and RAM are a tad low for using GParted, too. Not wanting to find if I could hunt down my copy of Norton Ghost, I opted to use a different machine for cloning. I’ve got a faster Pentium 3 stashed away, anyhow. With a USB port, too! Fancy! I even broke out my M2 keyboards for the occasion.
Image in hand, I wonder: can I load files from the image using a file recovery software? Surely I’m not the only one who’s needed files from an obscure file system, right? Unfortunately, searching for options brings up a plethora of results for a “Theos cross-platform build system” program compiler project that started a few years ago. Why they chose that name, I have no idea. Ultimately, the most recent information I could find on THEOS the operating system at the time was from 2002. No file recovery software, no linux filesystem tools, nada. So… will this run in a virtual machine? Maybe I can use screen capture software to extract the information I need, or at the very least figure out what files I need to find.
Well yes, but also no. Turns out it looks for a particular chip to be inserted into the computer’s DB-25 (LPT) port as a form of anti-piracy protection.
Ah, 90’s-era anti-piracy measures. I’ve not missed you. Some companies still use stuff like this for expensive software licensing (nowadays they’re on USB drives), but finding something like this for an old operating system is new for me. My work computer does not have a DB-25 port, so I was not able to forward the hardware to the virtual machine. Not that I needed to in the end, but it would have been nice. I’ve blurred out the serial number here, since it’s theoretically possible to trace it back to its owner if those records still exist somewhere, but it looks something like 102-12345.
Well, what else can I use the image for? How about I take a peek at the disk to see if I could manually extract what I needed?
Jackpot. Sorta. The files on the disk seem to be null-padded binary streams, but they’re pretty simple to decode once you work how many fields there are and how large each one is. Especially since most of the data is ASCII text. For manually extracting files from the drive image, one aspect that makes things easier is that most of the files are visually identifiable. The drive is formatted in such a way that the empty space is just a repeating sequence of bytes: 0110111011100110
This makes it easy to verify if the spot you’re looking at is null space or a file, but simultaneously doesn’t guarantee that the file you’re looking at isn’t shorter than what you’re seeing - the null pad only happens on format, not on file erase. I found a few instances where a larger file was overwritten with a smaller file, so the end of the file was more or less garbage I’d have to manually decipher to figure out the actual end of the file. I did happen upon the minimum allocated block while using this trick to browse through files: 265 bytes.
The trouble then becomes working out how to find all of the files I need and how long each of them is. And what data means what. While browsing through the disk dump, I find some source files referencing a “ZIP.DATA” file. Maybe if I can find that file, everything else will fall into place? This requires more investigation.
At the head of the disk, there’s a classical MBR record with a single partition. Due to the size of a sector there's a sizable null-zone before the actual partition starts. The next thing on the disk is what I presume to be a chainloader for the file system, then there’s a file allocation table.
File names seem to be stored in a space-padded 16 bytes, with 8 for the first part, and 8 for the second, or what we would call the file extension. A file entry is 64 bytes total, presumably with data such as date, time, filesize, and location in there somewhere. Unfortunately, there also seem to be a large number of “ZIP.DATA” files. This is going to be a bit hard to decipher with the little information I have, especially since I’m not too keen on reverse-engineering the bytecode to figure out how the system runs. To the dinosaur dig!
For the majority of a Saturday afternoon and late into the evening, I worked through some of the mysteries of the system with help from a friend, teasing out the operational workings of the system. For example, there’s a FILELIST command in the help screen, but running that command returns without printing anything to the screen. Digging deeper into the documentation available, we found that you have to specify which file pattern to list out, and optionally which drive to list from. It uses a curious syntax, though. Using FILELIST *.* shows all of the files on the drive.. mostly. Well, files that have been user-created. It doesn’t show files that you don’t own. Having seen the file table myself, and also knowing that there’s a custom program on the machine that’s not showing up in that listing, we dig a little deeper and discover that a portion that we had thought was an example optional argument was in fact the actual syntax. The command to list all files and all “library” file members on the machine is FILELIST *.*.*:S (PUBLIC - easy, right?
The way this system stores files is mostly flat, no folders. It supports folders, but doesn’t seem to actually use them. It prefers to use “Library” files instead. I’m not entirely sure what the difference is, aside from how you reference them. They store their member files in very much similar format on the disk. According to the documentation available, you’re supposed to use libraries to “group files that are similar in nature” - you know, like what most people use folders for. The system won’t let you store other libraries or folders in a library and gives you control over the initial table size, which is probably the biggest difference. What is most interesting about the system, though, is that it natively supports a database file format. Those null-padded files I discovered on the disk aren’t due to any special programming in the accounting software, but are rather data files that the system itself supports out of the box! Neat!
We eventually find how to copy files to a floppy drive, but, as with all things with this system, there’s a catch: the floppy must also be formatted in THEOS format. It won’t read a FAT-formatted floppy disk. Welp, it’s better than nothing! We start by copying files one by one, one file to a floppy, then cloning the floppies using rawwritewin running on an XP box for later analysis. Eventually, though, we also discover that the FILECOPY not only has the (PUBLIC option, but it also supports a mysterious (EXPORT option that’s supposed to export files in a DOS-compatible format. We very shortly discover that it simply means that it exports database files, which it calls “Indexed” files, into a comma-delimited text file format.
FILECOPY DATA.*.*:S DATA.*.*:F (PUBLIC EXPORT
Score!
Feeling a little braver, we try to copy an entire database library onto a floppy. It takes about 6 hours to complete due to how it writes: find a free spot, write to the file table, write a 256-byte chunk, update file table with file size metadata, repeat. Given the size of the file portion of the disk, this means it could take 11,392 write head position changes to fill a floppy disk. Floppy drive heads are not quick. Amazingly enough, all of the files for the specific database we needed just nicely filled one floppy. Which is really fortunate because, as I discovered later, the FILECOPY program doesn’t ask you for a new floppy if you run out of space - it just skips to the next file and ignores files that are too large to write.
Act 3: The technical bit
So now that I have all of these files in an image dump, how do I get them out of there? I really don’t want to manually export by hand the 120-some files that are now contained in this itsy bitsy image file. Plus, what were to happen if we needed more files later? The system writes files sequentially and uses the first available free disk space, but picks a random free slot in the file table when writing files, so the order of files in the list won’t match the order of files in the disk. Keeping track of the order of files being written isn’t a great use of time, especially when some libraries can take six to twelve hours to write to a 1.44MB floppy disk. And I’m pretty sure I missed some while keeping track of the first batch.
Solution? Reverse engineer the file table, of course!
Before I get too far into this portion, I’m going to explain a little about how computers store data. Disk partitions are set up by a partition table not too dissimilar to a file table, but THEOS doesn’t use partition tables, so I’ll skip that bit. Once you’re in a partition, one of the first blocks of data stored is an index of the files stored on the storage medium. At its most basic form, it can be thought of as a chapter listing at the front of a book: There is a file named X that you can find if you skip to position Y that is L bytes long. There’s more there, too. If you’ve ever looked at a file’s properties, all of that information you can see there - the location, size, size on disk, created, modified, accessed, security access, file attributes - are all stored in this file index table. (If you’re looking at the properties of an image, extra data such as image resolution, size, etc is stored in the file itself).
Anyone familiar with computers will also know that data is stored in a binary format - when a computer reads a text file, they are simply looking up what value 65 is supposed to look like on your display screen and sending to the display driver instructions to change pixels on the screen to match the A glyph you’re familiar with. Computers don’t know what text is - not on an intrinsic level. Computers read numbers and look up what those numbers are supposed to mean on instruction tables. Computers read and store numbers as sequences of 1’s and 0’s, otherwise known as binary.
Here’s the next bit of knowledge that will come in handy: we humans tend to read numbers from right to left. I don’t mean the names of numbers, mind you - I mean how the powers are arranged. 123 base 10 is 3 * 10^0 + 2 * 10^1 + 1 * 10^2. In mathematics when you are reading numbers in other bases, this rule remains constant. 123 base 8 is 3 + 2 * 8^1 + 1 * 8^2. If you were to try to translate binary 01001000 01000101 01001100 01001100 01001111 into text, you’d start by converting each sequence into numbers. Pro tip: you can actually ignore the upper three bytes when converting binary to ASCII. Uppercase is a 0 in the 32’s position, and lowercase is a 1.
01000001 is an A
01100001 is an a
Binary is then read from right to left in sequence: 1, 2, 4, 8, 16, 32, 64, 128, etc. The value that most impacts the final value is on the leftmost position. This is known as Most-Significant order, or in binary “MSB” (Most Significant Bit). In this example, throwing out the upper three bits, we have 01000 00101 01100 01100 01111. Counting from right to left, the first number is easy: it’s the 8th letter of the alphabet. H. Second is 1 + 0 + 4 = 5. The 5th letter. E. The next two are the same, no 1’s, no 2’s, one 4, one 8, 4 + 8 = 12. L. Last character is 1 + 2 + 4 + 8 = 15. HELLO!
Storage controllers store data in 8-bit segments known as bytes. A byte can only count from 0 up to 255. That’s not particularly useful when we need to be able to count big things, like how much money you have in your bank account. So computers chunk bytes together to get bigger numbers. An Integer (a whole number) is four bytes squashed together, and can count all the way up to 4,294,967,295. Not quite up to Jeff Bezos. A long integer on a modern 64-bit system is eight bytes, which can count up to 18,446,744,073,709,551,615. That’s a number large enough you could count all of the money on earth, hundreds of millions of times over!
To make working with computers a bit easier, we use a 16-base writing system known as hexadecimal, or just “hex”. 0 through 9 are just as you’d expect, but we also have A = 10, B = 11, C = 12, D = 13, E = 14, F = 15. A value of FF in hex is 255, or 11111111 in binary. If you were to write the number 12345678 as a hex number, you’d expect a value of BC614E (trust me on this here). Because bytes conveniently fill out every two hex digits exactly, the bytes are then BC 61 4E.
Now, the order that bits (the individual 1’s and 0’s) in a byte are written and read from storage mediums are nowadays handled by the storage controller (and thankfully this system is “modern” enough to have an IDE drive, as IDE drives were when that control was relegated to the drive itself rather than the computer), but the rest of this bit of information becomes most relevant when I mention that computers don’t always read numbers from right to left in the LSB to MSB order we’re used to seeing. A lot of systems, especially older ones, read numbers from left to right. Instead of writing the biggest part of the number first and working their way down, known as “Big endian” format, many computers and computer programs tend to write numbers starting at the lowest digits first. When you read and write from the least significant byte to the most significant, otherwise known as “Little endian,” it looks like you’re reading the number backwards. Our value of BC 61 4E would look like 4E 61 BC when looking at the disk. This can be a bit counter-intuitive, because we don’t normally read or write numbers like “123” as “321” in everyday life.
This can make finding and reverse-engineering binary streams significantly more difficult as well, since not only do you need to figure out which bytes mean what, how many fields there are, and how many bytes you need for each field, but you also need to figure out if numbers are stored in big-endian or little-endian format. Ultimately, this means a lot of guess-and-check coupled with a not-insignificant amount of pencilwork.
Act 4: The THEOS32 File Table, Unraveled
With all of that ado, I’m just going to gloss over most of the order of events that got me this far into deciphering the table itself. The floppy images that I made first while testing turned out to be a great help in deciphering the locations of fields such as the position and file size, and I was able to translate those over fairly well to the full dump of the export files as well as the hard disk itself.
The first thing that jumps out when looking at the file table is the filenames - ASCII-encoded, they stick out of the binary data like a billboard in a cornfield. In fact, the spacing for the filenames was how I first figured out how large the file records are: 64 bytes. Filenames are stored as two 8-character strings, with the 2nd part of the file being all spaces for files where an extension isn’t defined (in the main index) and all nulls if it’s a library file member (more on that next). These are stored almost just as you’d expect, from left to right and with spaces padding the empty space. I’m not sure why the file names aren’t null-padded, but it works. Also made it really easy to tell how large the strings were supposed to be.
As far as I was able to determine, there are 10 different types of files possible on a system:
- Program (assembly program)
- Index (database file)
- Relative
- Stream (any data stream, usually a text file)
- Folder (similar to a library)
- System Program
- Library (Collection of database files)
- Member (Member file of a library)
- Deleted
Yes, the file table even tracks deleted files. My going theory on this is maybe it tracks the empty spots for later cleanup with another utility, or perhaps it evaluates if the space leftover by a deleted file nicely fits a new file to be written? In either case, and rather by accident, I found that any file marked as type 0xFF could be ignored entirely, since I wasn’t looking to recover deleted files. I never did figure out what a “relative” file is supposed to be. Most samples I could find were just null-padded files, and the user manuals had no information about them other than the fact that they exist. They do have a record length, but not a key length, which makes me wonder if it’s a simpler database format. The CREATE command doesn’t even support creating a relative file, which only deepens that mystery.
Indexed files are the null-padded database files I discovered earlier. The index table includes the size of each record and the size of each key. There’s more data in the index file itself about how to read them, presumably in the first 14 bytes, but I didn’t need to work out that portion since I had the export option.
Folders and Libraries share a rather interesting quirk. Remember how I mentioned that I had well over 100 files on a single floppy, and how it had taken nearly all night to complete writing it? Well, as it turns out, the file table for a THEOS floppy isn’t physically large enough to hold file records for 100 files. With a block size of 256, and a record size of 64, we have an available space of 4 records per block:
THEOS keeps track of the disk’s cylinders, heads, and sectors in addition to disk label and other misc data. The 256-byte block that tracks this information is kept just in front of the partition table itself. On a floppy, it’s 1024 bytes from the start of the disk. Leaves a bit of wasted space, too, since a boot sector is only 512 bytes. It would seem that the 512-byte space before the disk information is intentional space for including a boot chainloader and they just didn’t think to leave that space offset out of non-system disks. Or they didn’t want to make a different format for storage disks vs THEOS boot disks, I don’t know. On a hard disk, though, it gets even weirder: the partition table doesn’t even start until 32256 bytes after the 1024 byte offset. 31 KiB of empty space. On an addressing format incapable of addressing more than 4 GiB of disk space. Well, beggars can’t be choosers? It’s just how it is. I’m fairly certain this is due to physical disk sector addressing and they didn’t bother trying to reclaim the unused space from the rest of the sector, not that they really needed to. The floppy format is still more efficient than FAT, though - 1471744 bytes to be used for files vs 1457152 for FAT. 14.5K extra storage is quite a nice bonus.
Anyway, see those three bytes I have marked as the Index Allocated? That’s the number of blocks that have been allocated for the file table. A block is 256 bytes - divide that by 64 bytes per file record, and you have 4 records per block. So take the number of blocks multiplied by four and you have the number of individual files that the system is capable of storing. The 05 00 is stored in little endian format, which means it’s 0005 in hex. 5 * 4 = 20 records. 00 7B 01 for the hard drive is hex 017B = 379, which is multiplied by 4 gives us 1516 slots for file records.
No, that scratch isn't on your screen, it's on my bench monitor.
Free is a pretty good price, though - can't complain.
A floppy is only capable of storing 20 files, total!
So how did I manage to get over 100 files onto a floppy without the system blowing up? Turns out the system has a really neat loophole for getting around this limitation: when it creates a library file or a folder, it creates a new file index as a “file” for the main file index, and stores that file index as a file itself. So you can have multiple file indexes located all over the disk, not just at the main file table. In order to use disk space and processing efficiently, it’s also best if you have an idea for how many records you’re planning on storing. These files have to be sought out and loaded fully before the system can use any individual file referenced in there. More on that later, since that’s not important right now. We’re still trying to figure out the main bits here. For the purposes of file recovery, though, this quirk means that we have to be able to load these extra file tables as well as the main index before we can be sure we have the full file listing.
The next bits we need to figure out (or bytes, rather) are the location and the size of the files. This was easy enough to work out after comparing the floppy images with the data provided from the FILELIST command. Interestingly, both the file size and the block allocations are stored in the file table, even though these numbers are usually in the same block. (The reason why this is becomes apparent later in deciphering the table). These numbers are stored on disk in little-endian, so you need to read them lowest-order first. At this point, this is the information we know:
The record length and key length fields were pretty easy to figure out, simply comparing the system’s file listing with the file index. It is right between the fields for file size, after all. Found by chance, really, since I wasn’t actually looking for those numbers. Off to the right are more bytes, but usually they’re nulls. The very last byte is usually 03, but sometimes 00. That last byte was one of the last ones I figured out, mostly because it has absolutely no bearing on the file’s existence, try as I may to isolate its purpose.
See the bytes I have marked as Modified Date?? I’d figured this out by comparing file records and what changed and when, but at this point I still didn’t know how to read it. It seemed to be a big-endian number, based on which bits were changing as the file dates changed (the right-most bytes changed first, and seemed to count progressively up as time passed). The only value stored in big-endian in the file header, or anywhere else I'd found on the system. Interestingly, it seemed to count seconds, even though the operating system would not print out the file modified date with a resolution to show seconds.
My first thought was maybe this is simply the number of seconds being counted. It’s the most efficient method of storing a time (bytes utilized vs the amount of time that can be measured), and the times were close enough to be seconds. However, when mapping out the seconds to times to try to map out what the offset should be, things started to get weird. Times didn’t match up with files adjacent. Files written at the start of a day were drastically different from files at the end of a day. The values continued to count upwards, but the rate at which they counted up was itself variable - an extra second every 7 or 8 seconds, or even in-between. I was able to confirm that the first two bytes were definitely tied to the date and the right two bytes were tied to the time of the day, but none of the methods I tried in using the bytes as numbers translated to anything coherent.
I then had the idea to break the bytes down further into binary, just to see what bits were set up and how they were laid out. This is when I made a breakthrough into the date storage format: it wasn’t a number at all! It’s a series of exact-size number fields squeezed into a binary stream!
6 bits for the number of seconds. (0-63)
6 bits for the number of minutes. (0-63)
5 bits for the hour of the day (24-hour clock). (0-31)
5 bits for the day of the month. (0-31)
4 bits for the month of the year. (0-15)
6 bits for the number of years since 1986. (0-63)
They stored six numbers into a space you’d expect to see only one or two. This has some interesting consequences: since we’re storing the exact numbers, we don’t need to do any calculations to decipher the calendar date from an offset, we just trust that the system calendar had the correct date when written. Binary operations to extract those numbers are very quick compared to the multiple division operations and some table lookups to determine a date from a seconds count. We also save 4 bytes while keeping our direct number method, freeing up valuable file record space. File modification dates are written after the system has completed writing all of the data, too, so the seconds value is always a tad off when writing to a floppy.
Unfortunately this method fails when trying to translate the part of the partition label that I’m sure is used for the recovery date. The day and month line up, but the year is wrong. Maybe the offset year for backups is different from system files? If so, the offset year would be 1995, which seems to nicely line up with THEOS32’s release. Not sure why the system would use two different offsets for dates, but I would presume to assume it would be related to disk backups being new to THEOS32. Could be wrong as I only had this one system to work with and didn’t particularly feel like risking the integrity of the data to sate my curiosity.
All of the important bits done, right? We have the file size and the location, and we even cracked the file date for funsies. Let’s roll!
Except, some files I was recovering from the disk image weren’t quite right. While spot-checking some of the data I noticed that some of the files seemed to be getting cut short. Words or numbers getting cut before the line finished. I double-checked the file extraction code, and that was definitely the whole file. Kinda. The whole file that was stored in the blocks referenced in the offset. The file just ended at the 256-boundary. The most notable example of this was the SYSTEM.THEOS32.ACCOUNT file - a system file where THEOS32 v4 keeps all of the account and login information for the operating system. It was missing the user account that I had been using to log into the machine with. Something was amok.
Re-examining the file table, I noticed that the files that were messing up had more data after the block offset bytes. I had previously been ignoring those fields since they were always null when examining my floppy images, but I noticed a pattern: the extra data always lined up in 5-byte increments. The same number of bytes needed to store an offset and block size. Sure enough, after parsing the integer values and jumping to the blocks indicated, there was the rest of the file! I added code to load all of those extra blocks together, looping to the end of the file record for 6 fragments (one byte leftover, plus the end byte), and ran again for just the oddballs. Most of the files then loaded correctly, even the account file, but there were still some oddities. Some of the files had an allocated space in where I assumed was fragment #6, but an offset that claimed to be in the disk header space. Where absolutely no files should be stored, ever.
About this time, I happened across a security system vendor that happened to have a user manual for THEOS32 4.1 available on their website. Far more helpful than the 1985 manual for THEOS8. This turned out to be immensely helpful for finishing the filetable deciphering as it actually contained some clues as to how to expect the file table to be read:
So those last 6 bytes are not a file segment record at all, but rather are two optional pointers to a 256-byte block on the disk containing up to 51 more block segments for a potential of 107 individual file fragments for a file. The last byte in the file record is a number signifying how much more space should be reserved each time the file needs to be expanded to store more data, expressed as a % of the current file size. This “grow” marker is a floating point number expressed as two nibbles, 0-9, one for each half of the decimal. 03 would mean the file should allocate an additional 30% of the current size of the file, and 30 would be 300% (it doesn’t support mixed fractions like 330%). Not needed for file recovery, but still a really interesting look into how this system was designed to work.
With that work out of the way, I was finally able to fully load in the files from the file table. With only two remaining unsolved fields, why stop now? I wrote a bunch of dummy files to a floppy and used the CHANGE command to set the permissions one by one on each, then dumped the floppy image for inspection. Bitfield. Solved! User-Read, User-Write, User-Execute, User-Erase, Other-Read, Other-Write, Modified-Flag, Hidden-Flag, in that order. The users table I ended up getting a tad ambitious and actually loaded in the full user table from SYSTEM.THEOS32.ACCOUNT, just so I could print it out and make it look nice. Interestingly, user passwords are stored in 8 bytes, which theoretically means it should be trivial to crack. It clearly uses some byte padding mechanism, since most of the short passwords in the table had the same 3 or 4 last bytes.
The “Priv” number here is how the system segregates account permission levels. 5 is the super admin, do-anything account, 4 can make system backups, 3 is a general admin, 2 is allowed to write programs, 1 is a general user, and 0 can’t even save a file.
The fact that files are marked with their owning user combined with the fact that there are so many ZIP.DATA files with no folder brought the last bit of information to run file recovery: the system doesn’t have a singular file structure tree. Not in the way that modern systems do, where the admin or root account has access to every file on the machine. Here, if you aren’t the owning user, you can’t see the file. (Well, there’s probably some method to do so, but it’s pretty well hidden). There’s no reason for the system to bother with preventing users from naming files the same as another file owned by another user, because that user has no access to that file to begin with. No user folders. Everything is in the user’s root path. I added a bit of filtering logic to only extract files owned by the target user, and viola! No more file conflicts!
File Table Layout
Extended file blocks just repeat the size and position until the end, throwing out the last byte
And that’s about it! I did briefly venture into the world of trying to reverse-engineer the operating system boot code via a GDB terminal hook into QEMU and also briefly forayed into assembly code to try to find the password encryption code, probably 20 hours in all, but in the end those weren’t actually worth the effort. As interesting as it would be to crack, I really do have more productive things to get done. My goal was to get the files out, and to that end I was successful. I have no practical use for a THEOS password decryption utility, and I have no need to run a twenty-year-old machine in a container. Now all that’s left of this project is to reverse-engineer the old database schema and port it over to a modern database solution.
Somebody mention code?
In the interest of sharing with future googlers who may happen across this backwater blog in search of a solution to this oddly specific issue, I offer to you the script I created for extracting files from a THEOS hard disk image or floppy image: https://gist.github.com/jascotty2/940238522a1decd3dc39be6b64579487
Enjoy! ^.^
Resources:
Theos32 4.1 User Manual. THEOS32-4.1-SysRef.pdf.zip
HxD for binary file data https://mh-nexus.de/en/hxd/
Gparted or other linux for using the dd utility for full-disk imaging.
RawWriteWin for cloning floppies http://www.chrysocome.net/rawwrite
MBR format https://en.wikipedia.org/wiki/Master_boot_record
Partition type list: https://www.win.tue.nl/~aeb/partitions/partition_types-1.html
Handy calculator for hex conversions https://www.rapidtables.com/convert/number/hex-to-decimal.html